I am currently seeking full-time AI/ML Engineer, Research Scientist, Research Engineer, Quantitative Developer roles at companies that can support a Skilled Worker Visa in the UK. Please feel free to review my CV on the CV page.
Previously I worked as a Large Language Model Engineer, where I worked on projects at the intersection of machine learning, air charter services. I have also worked as a Computer Vision Engineer focusing on event-based vision.
I am interested in 3D generative models, self-supervised learning, score-based models, graph neural networks, multi-task learning, and leveraging sparse priors for 3D reconstruction. I draw inspiration from intelligence in humans and nature while I attempt to solve multidisciplinary problems using machine learning. I am currently experimenting with agent-based market making using large language models.
publications
Multi-task Learning for Optical Coherence Tomography Angiography (OCTA) Vessel Segmentation
Optical Coherence Tomography Angiography (OCTA) is a non-invasive imaging technique that provides high-resolution cross-sectional images of the retina, which are useful for diagnosing and monitoring various retinal diseases. However, manual segmentation of OCTA images is a time-consuming and labor-intensive task, which motivates the development of automated segmentation methods. In this paper, we propose a novel multi-task learning method for OCTA segmentation, called OCTA-MTL, that leverages an image-to-DT (Distance Transform) branch and an adaptive loss combination strategy. The image-to-DT branch predicts the distance from each vessel voxel to the vessel surface, which can provide useful shape prior and boundary information for the segmentation task. The adaptive loss combination strategy dynamically adjusts the loss weights according to the inverse of the average loss values of each task, to balance the learning process and avoid the dominance of one task over the other. We evaluate our method on the ROSE-2 dataset its superiority in terms of segmentation performance against two baseline methods: a single-task segmentation method and a multi-task segmentation method with a fixed loss combination.
Data Augmentation of Engineering Drawings for Data-Driven Component Segmentation
We present a new data generation method to facilitate an automatic machine interpretation of 2D engineering part drawings. While such drawings are a common medium for clients to encode design and manufacturing requirements, a lack of computer support to automatically interpret these drawings necessitates part manufacturers to resort to laborious manual approaches for interpretation which, in turn, severely limits processing capacity. Although recent advances in trainable computer vision methods may enable automatic machine interpretation, it remains challenging to apply such methods to engineering drawings due to a lack of labeled training data. As one step toward this challenge, we propose a constrained data synthesis method to generate an arbitrarily large set of synthetic training drawings using only a handful of labeled examples. Our method is based on the randomization of the dimension sets subject to two major constraints to ensure the validity of the synthetic drawings. The effectiveness of our method is demonstrated in the context of a binary component segmentation task with a proposed list of descriptors. An evaluation of several image segmentation methods trained on our synthetic dataset shows that our approach to new data generation can boost the segmentation accuracy and the generalizability of the machine learning models to unseen drawings.
Flaw Detection in Metal Additive Manufacturing Using Deep Learned Acoustic Features
While additive manufacturing has seen rapid proliferation in recent years, process monitoring and quality assurance methods capable of detecting micro-scale flaws have seen little improvement and remain largely expensive and time-consuming. In this work we propose a pipeline for training two deep learning flaw formation detection techniques including convolutional neural networks and long short-term memory networks. We demonstrate that the flaw formation mechanisms of interest to this study, including keyhole porosity, lack of fusion, and bead up, are separable using these methods. Both approaches have yielded a classification accuracy over 99% on unseen test sets. The results suggest that the implementation of machine learning enabled acoustic process monitoring is potentially a viable replacement for traditional quality assurance methods as well as a tool to guide traditional quality assurance methods.
The ability to describe an object in text or image and see it come to life in 3D form is empowering and revolutionary. Inspired by the origin story of Pixar Animation Studios, Can dedicated countless hours to mastering Unity, Unreal Engine, and Cinema 4D during his college years. Pixar’s journey, from its early days of bringing animated characters to life through computer graphics to becoming a powerhouse in animation, deeply resonated with him. By simplifying the process through text descriptions, we are democratizing creativity, opening up a world of possibilities for those who previously faced barriers to entry in the realm of digital creation.
Co:Sona, was born out of a desire to humanize large language models (LLMs), which we observed had become increasingly robotic and devoid of unique perspectives. We, Kelvin, Jacky, Kevin, Can, and Ganesh, sought to create a chatbot that could be tailored to any specific use case, capable of impersonating any character, figure, or model. We envisioned a platform where users could upload content to construct a unique persona for their tasks, thereby personalizing their interaction with the chatbot.
physyou is an asynchronous Telehealth platform for physical therapists to prescribe physical exercises, monitor the accuracy and completion rate of prescribed exercises. Patients can access the prescribed exercises and record their attempts in completing the exercise to verify the accuracy of their completed exercise.
COVID Analyst uses machine learning and spatial data analytics with a combination of reliable data sources and research publications to give you an address-level risk heatmap of COVID-19 in your area. In addition, it scrapes credible news outlets to give you a feed of news in your area and an AI-powered chatbot will answer any questions you may have about COVID-19.
PocketAnalyst is a Facebook messenger and Telegram chatbot that puts the brain of a financial analyst into your pockets, a buddy to help you navigate the investment world with the tap of your keyboard. Considering that two billion people around the world are unbanked, yet many of them have access to cell/smart phones, we see this as a big opportunity to push towards shaping the world into a more egalitarian future.

 Multi-task Learning for Optical Coherence Tomography Angiography (OCTA) Vessel SegmentationMedical Imaging Meets NeurIPS, 2023
Multi-task Learning for Optical Coherence Tomography Angiography (OCTA) Vessel SegmentationMedical Imaging Meets NeurIPS, 2023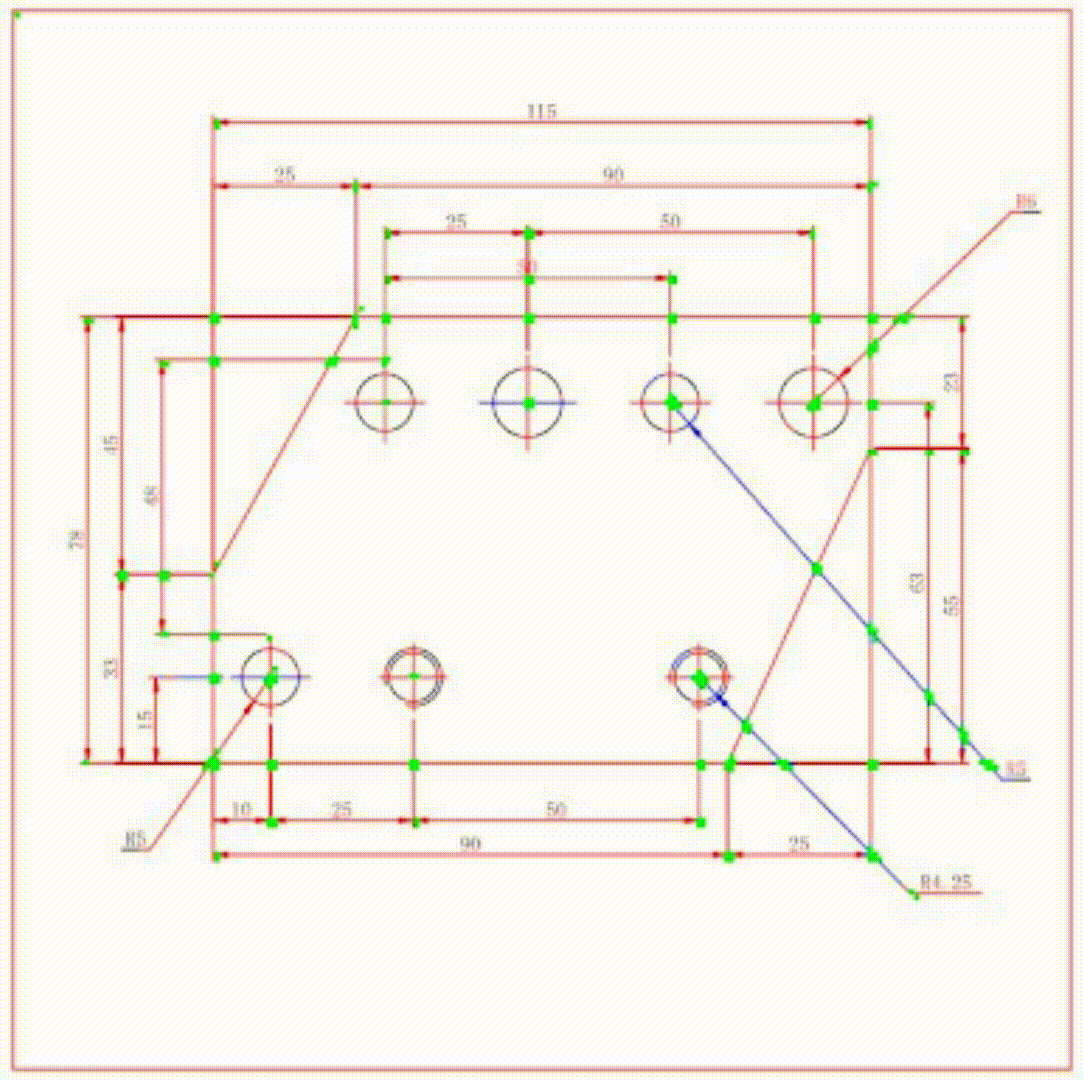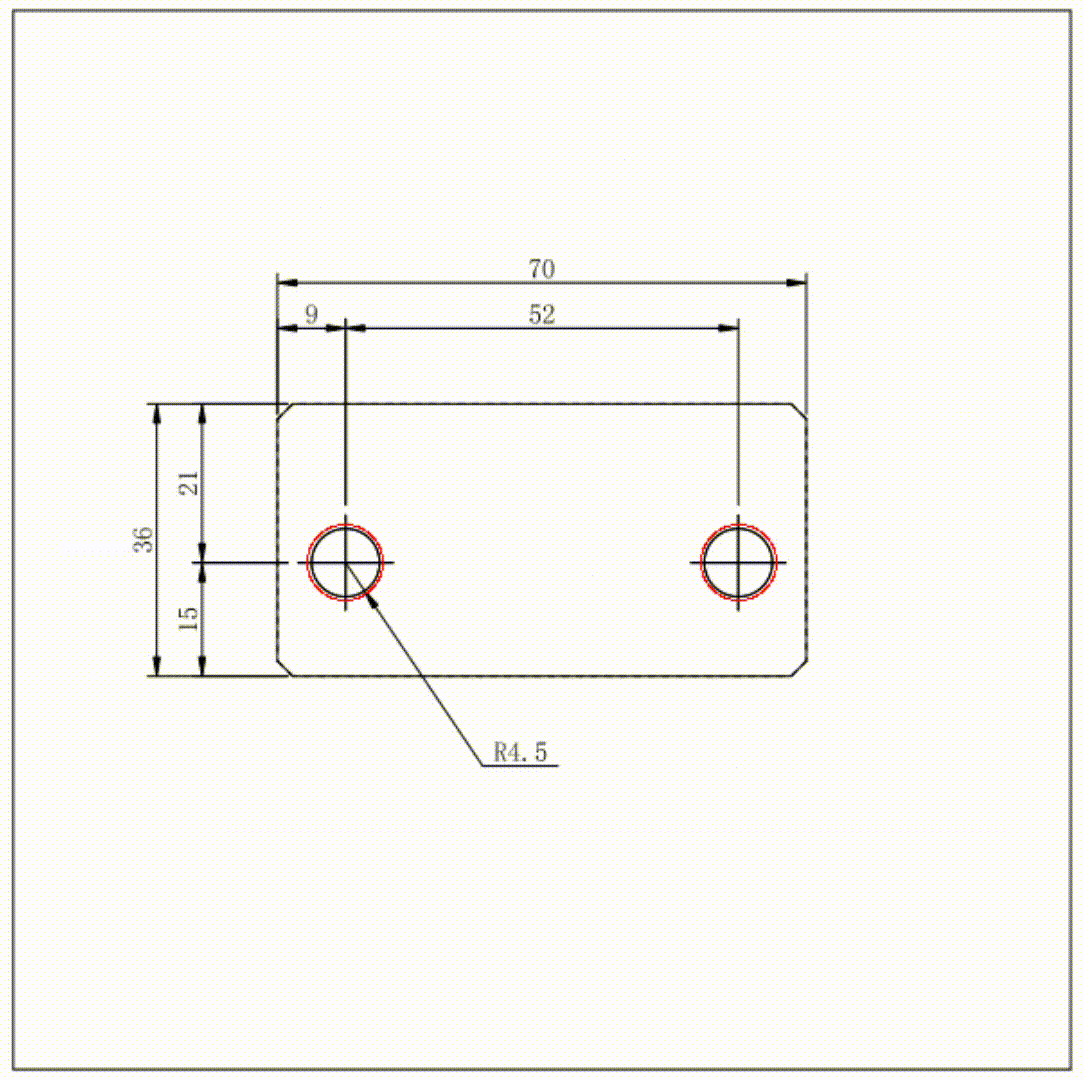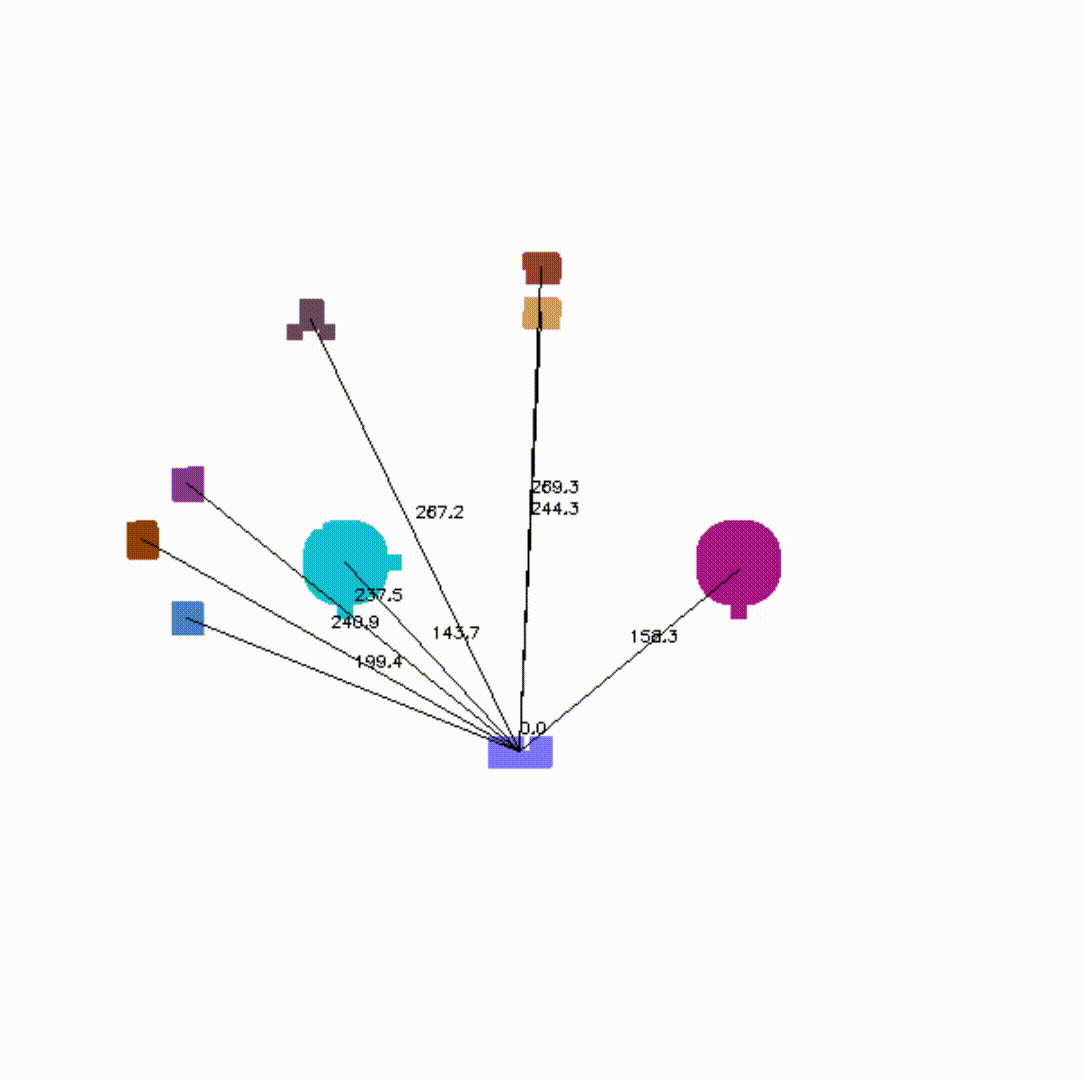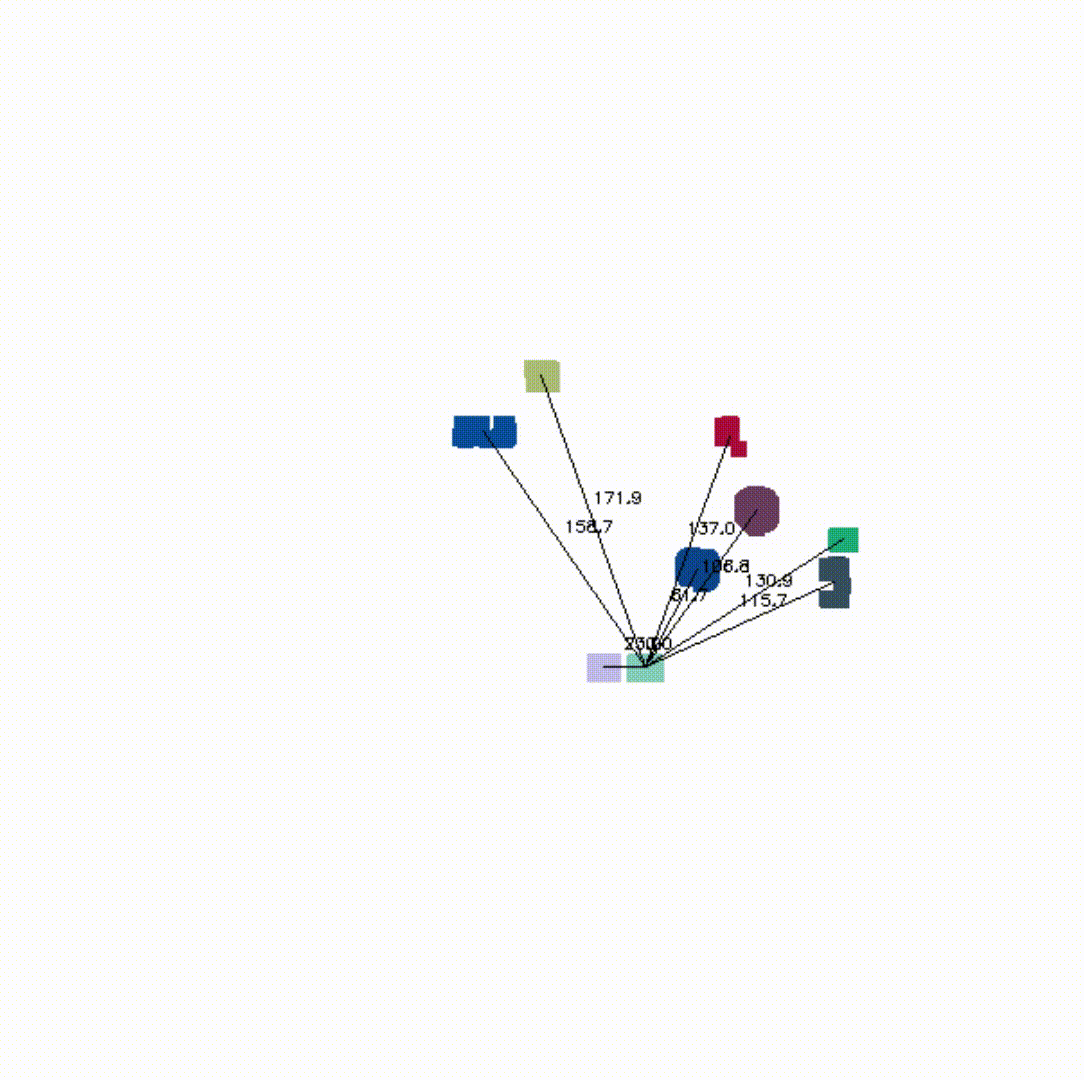 Data Augmentation of Engineering Drawings for Data-Driven Component SegmentationIDETC-CIE, 2022
Data Augmentation of Engineering Drawings for Data-Driven Component SegmentationIDETC-CIE, 2022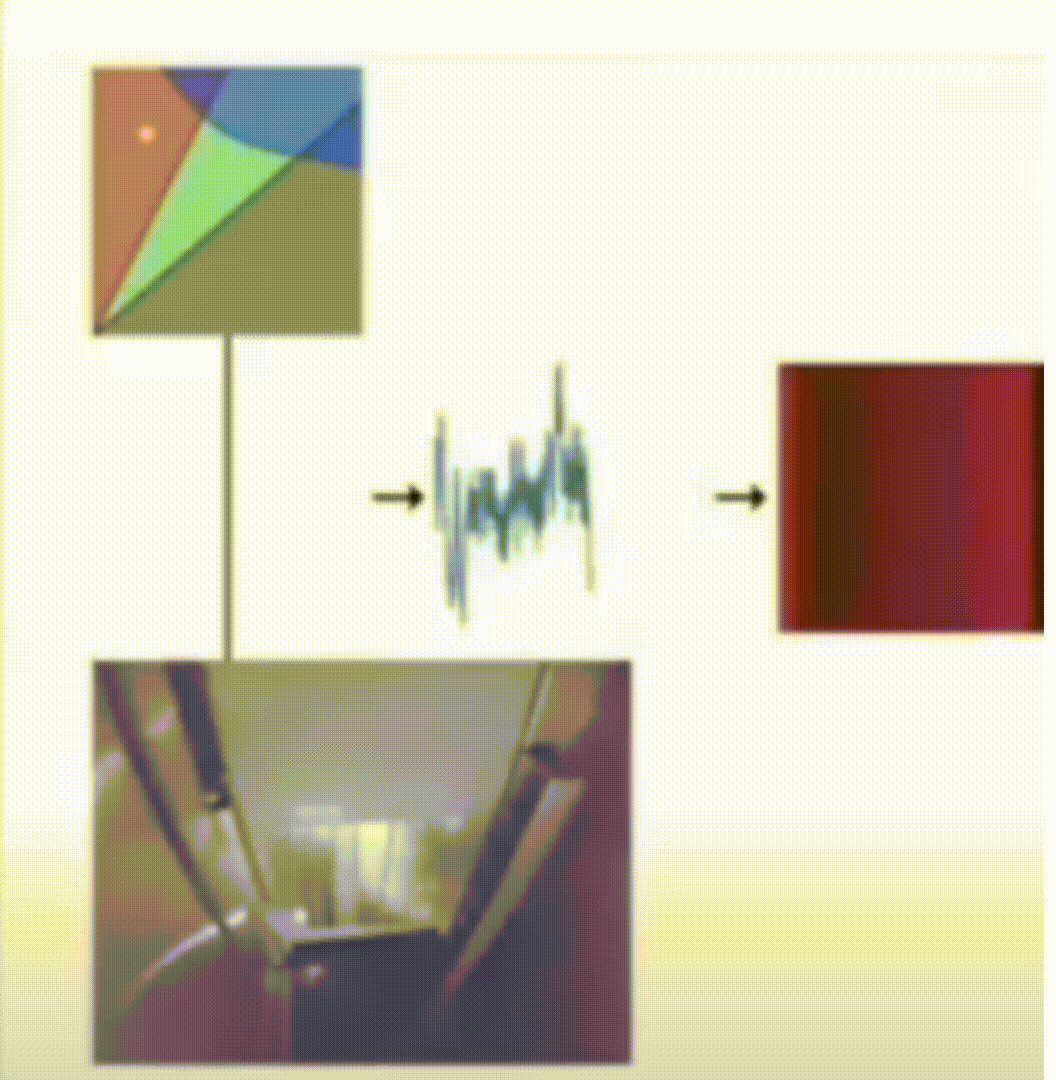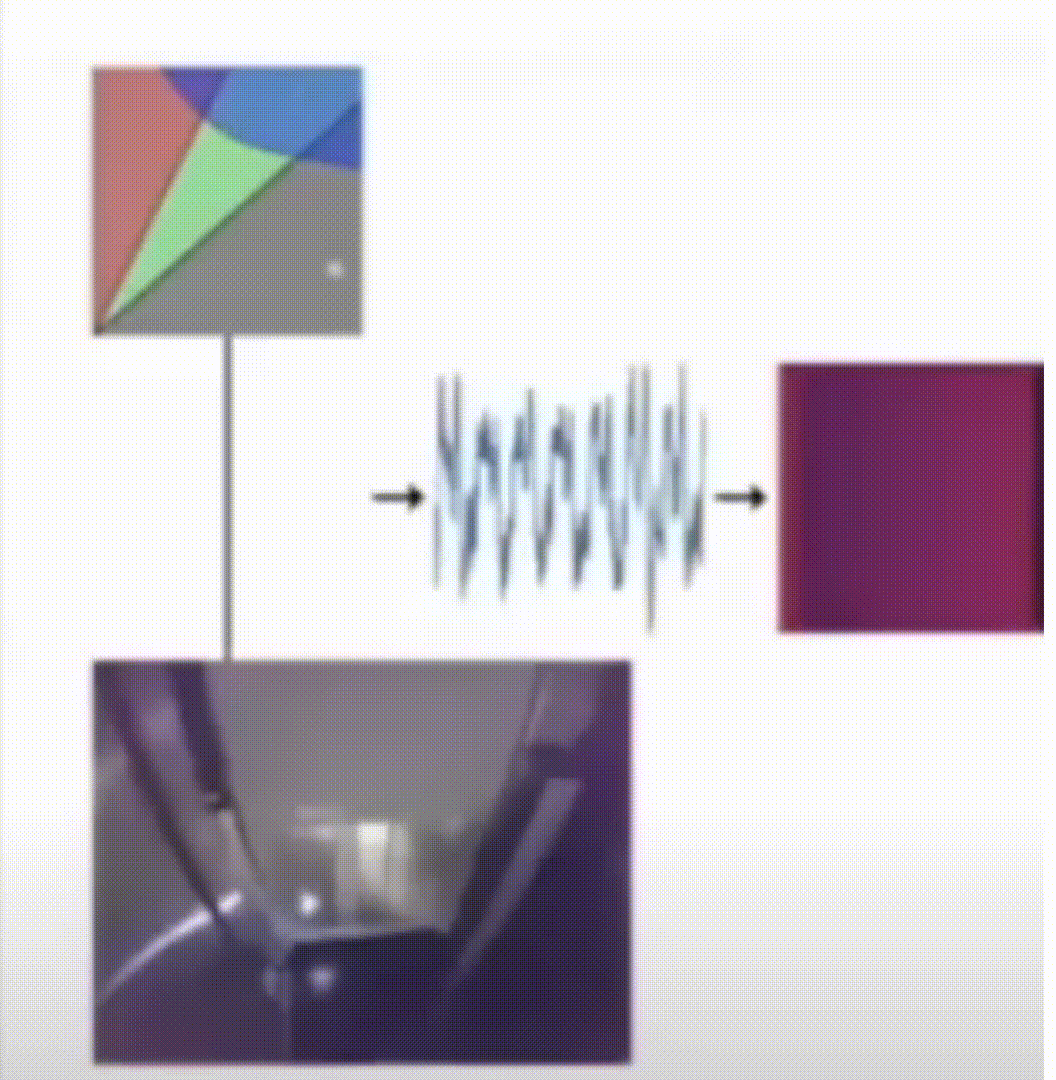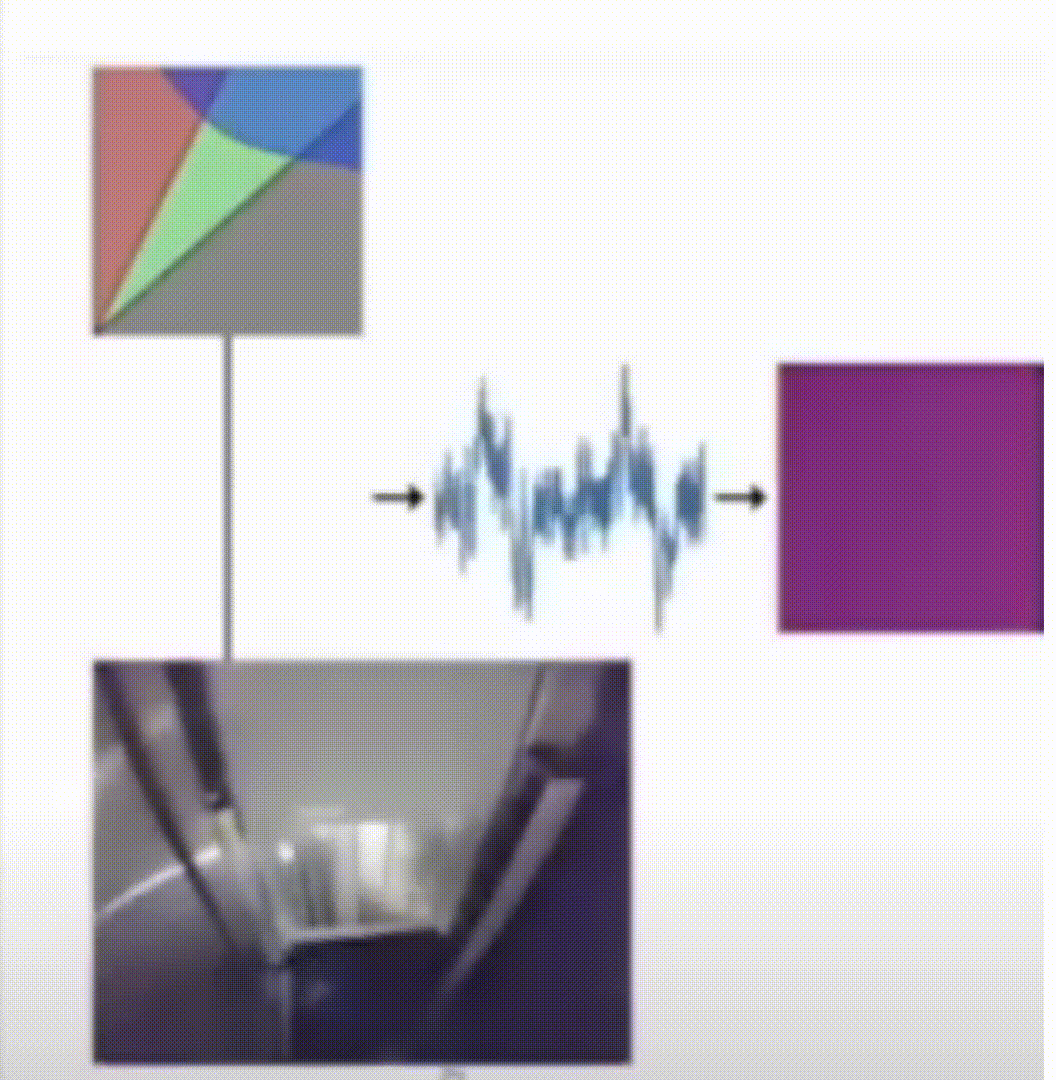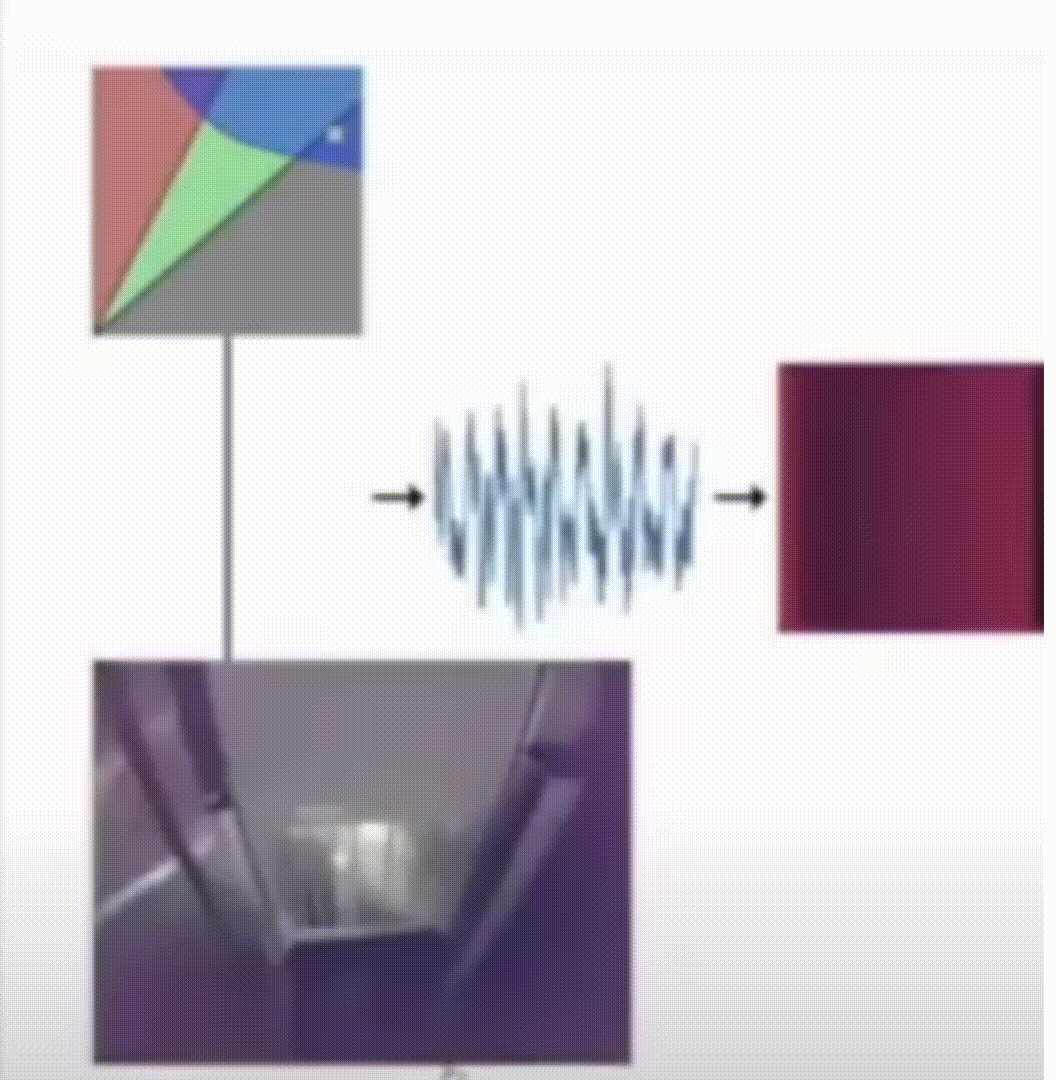 Flaw Detection in Metal Additive Manufacturing Using Deep Learned Acoustic FeaturesML4Eng @ NeurIPS, 2020
Flaw Detection in Metal Additive Manufacturing Using Deep Learned Acoustic FeaturesML4Eng @ NeurIPS, 2020







